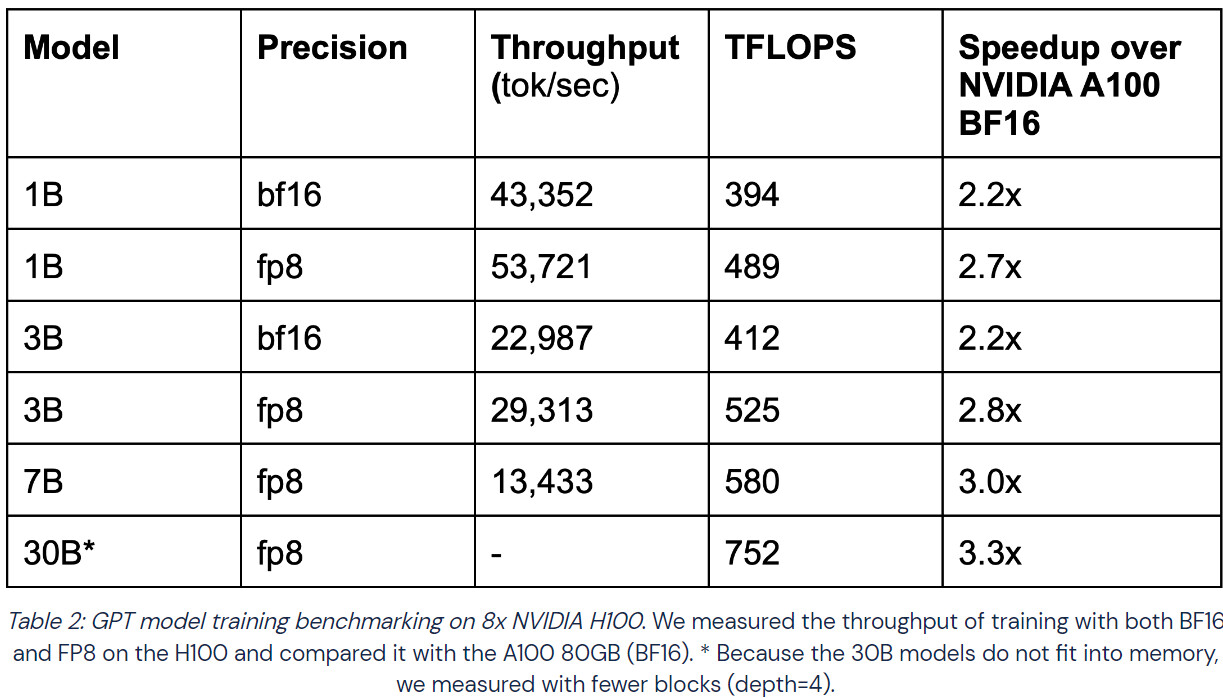
NVIDIA's H100 GPU is now available through Cloud Service Providers (CSPs), and MosaicML, a startup led by Naveen Rao, has benchmarked its performance against the previous generation's A100 GPU. MosaicML trained Generative Pre-trained Transformer (GPT) models of various sizes using bfloat16 and FP8 Floating Point precision formats on CoreWeave cloud GPU instances. The H100 GPU achieved a speedup of 2.2x to 3.3x compared to the A100 GPU. However, the H100 is 2.2x more expensive, with CoreWeave pricing it at $4.76/hr/GPU, while the A100 80 GB SXM gets $2.21/hr/GPU pricing. Despite the increased cost, the H100 is more attractive for researchers and companies wanting to train Large Language Models (LLMs) due to its faster training time and lower price for the training process. The tables below show a comparison between the two GPUs in terms of training time, speedup, and cost of training.